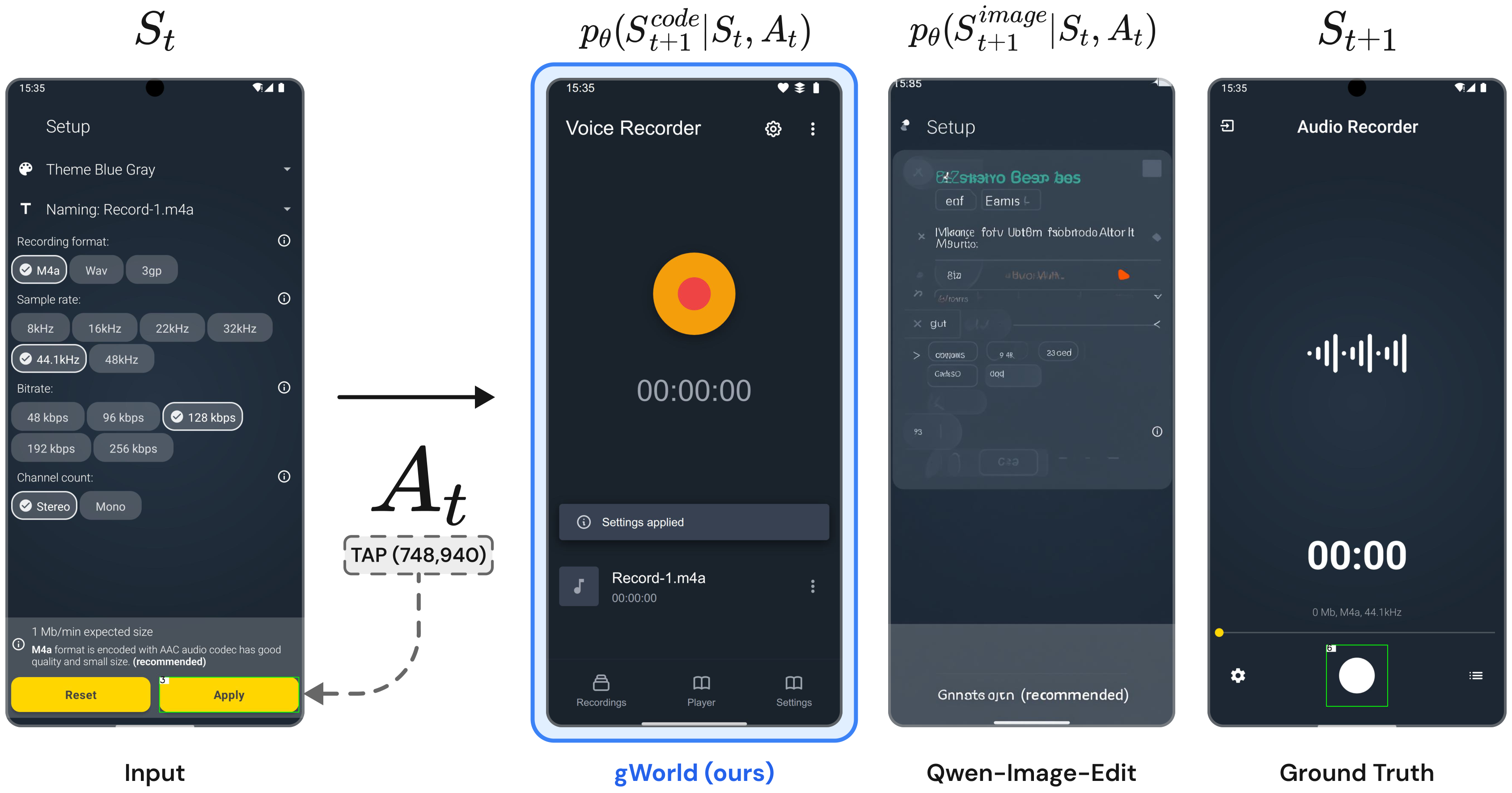
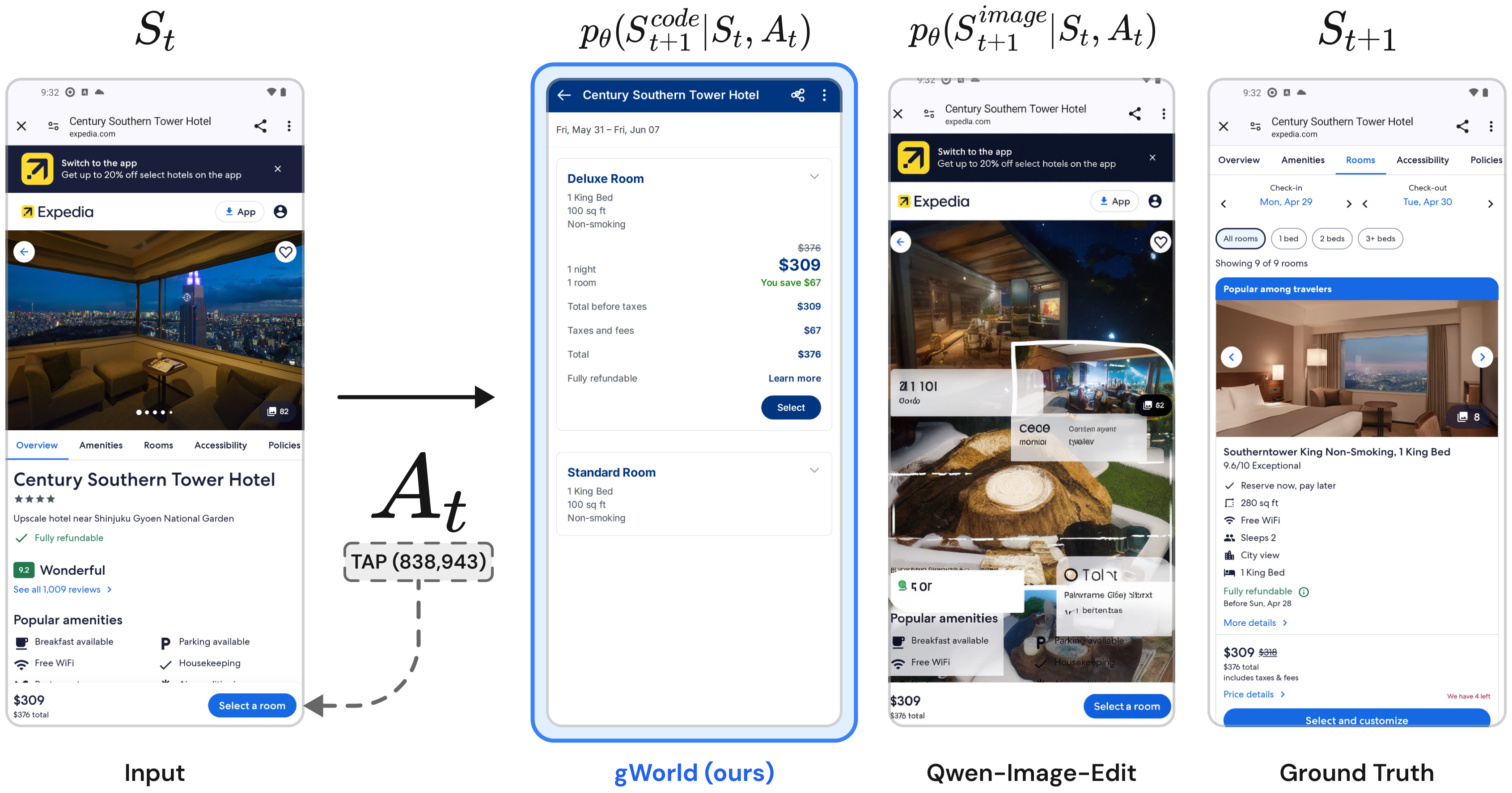
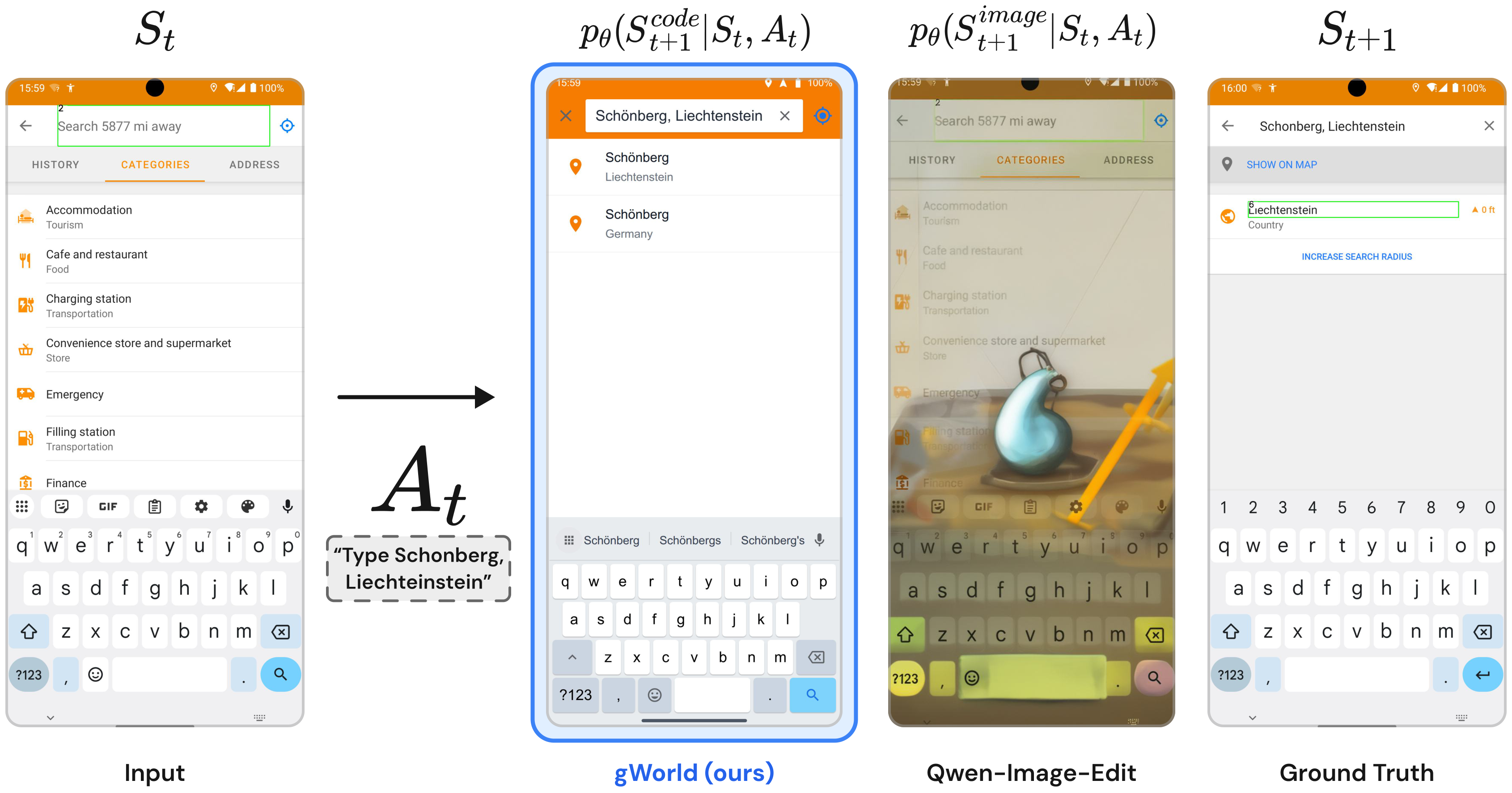
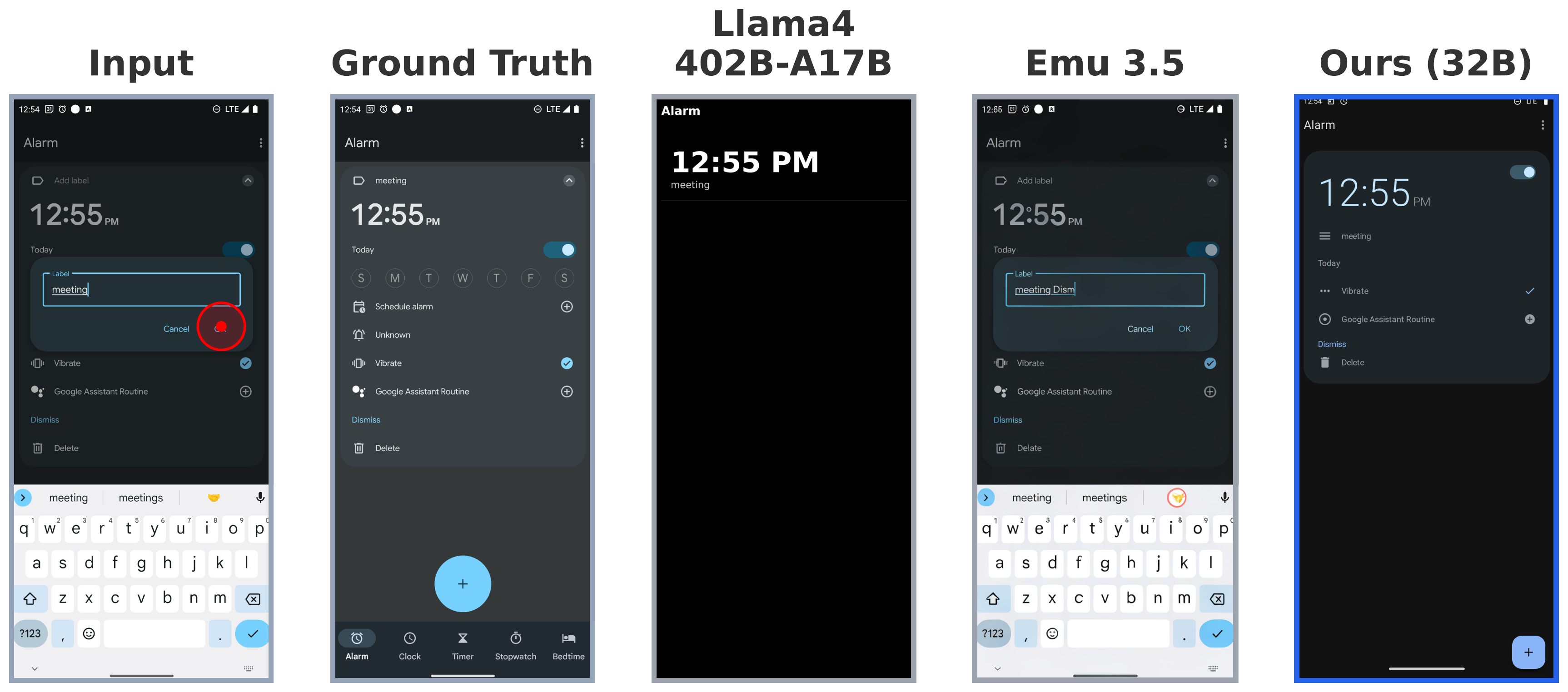
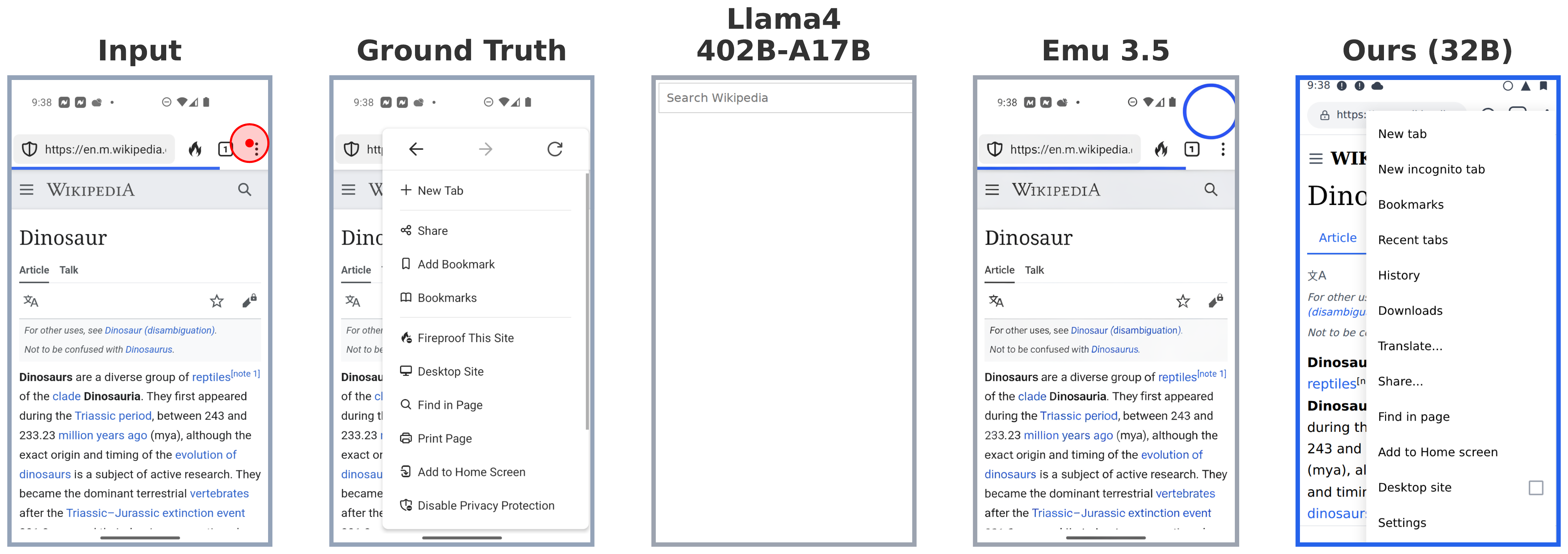
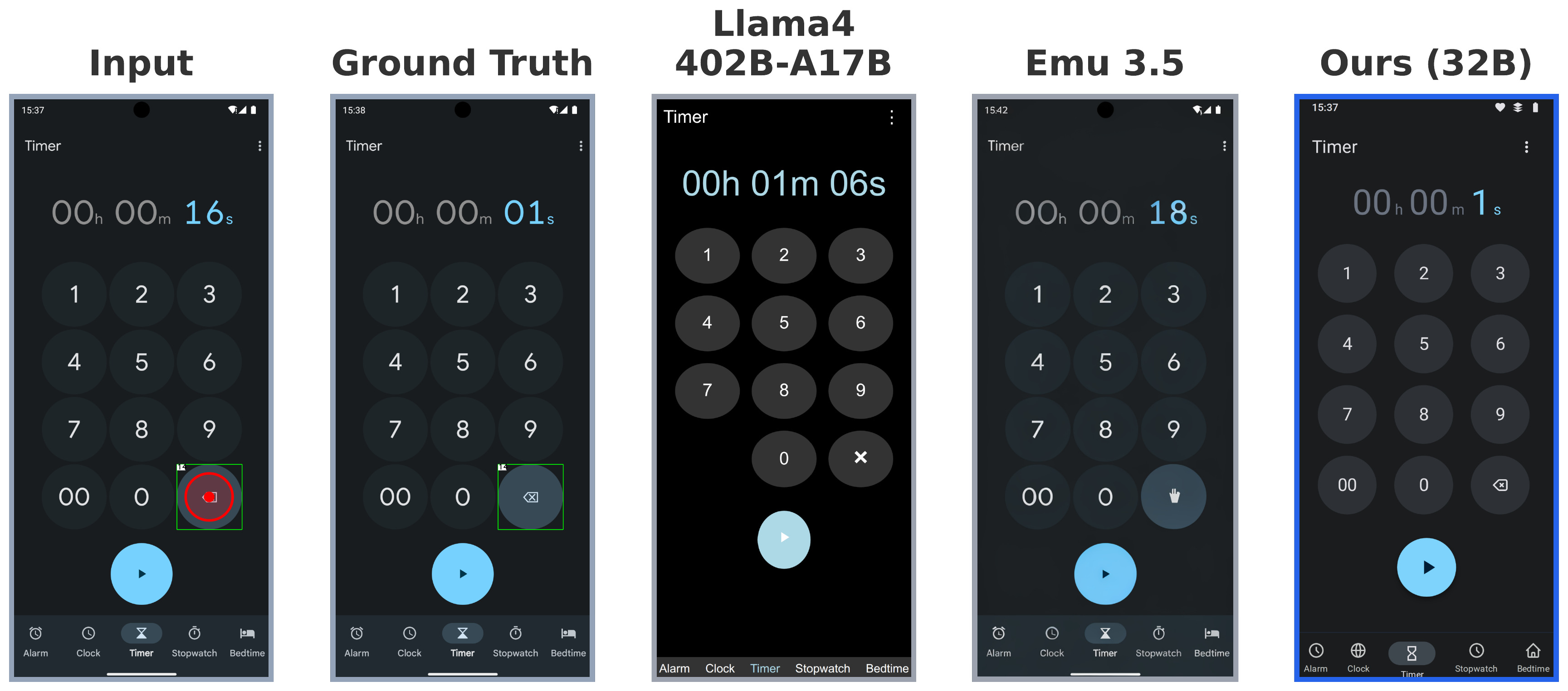
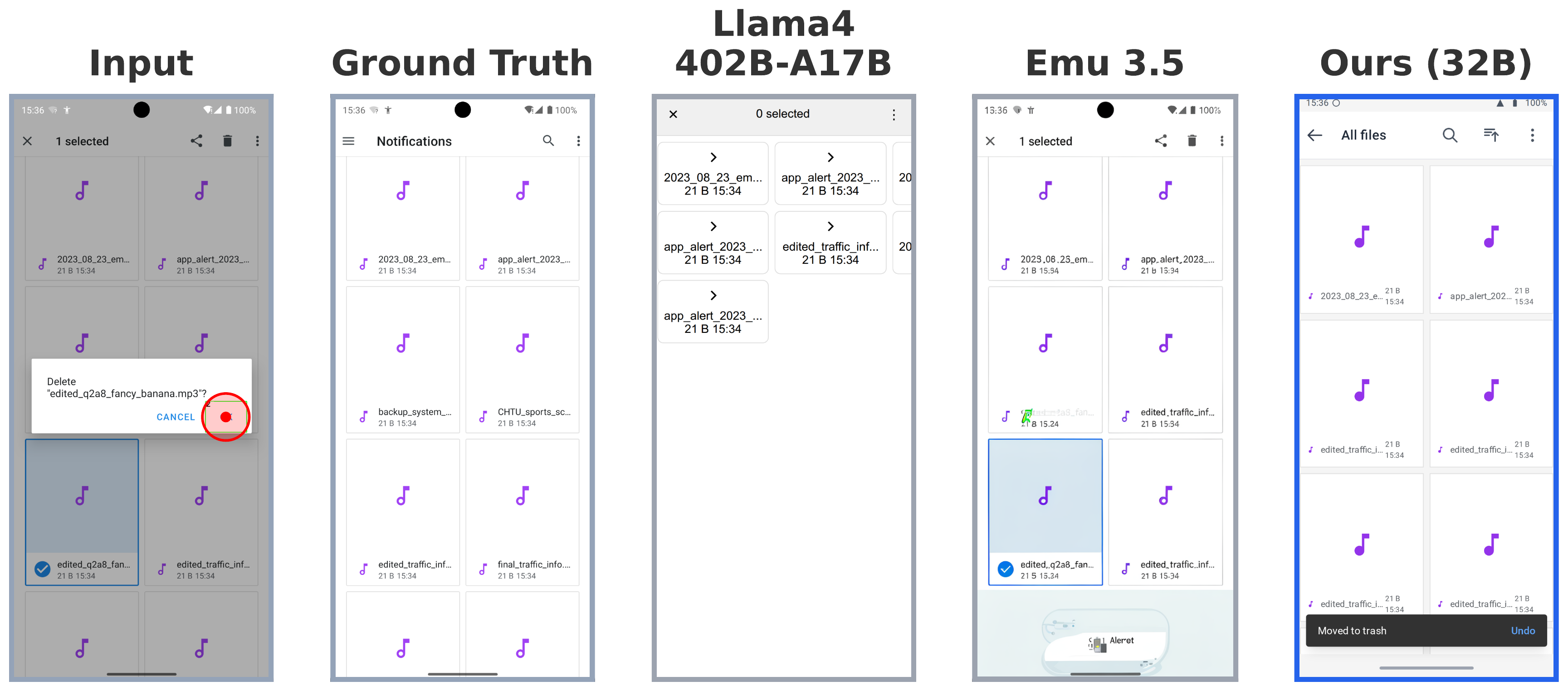
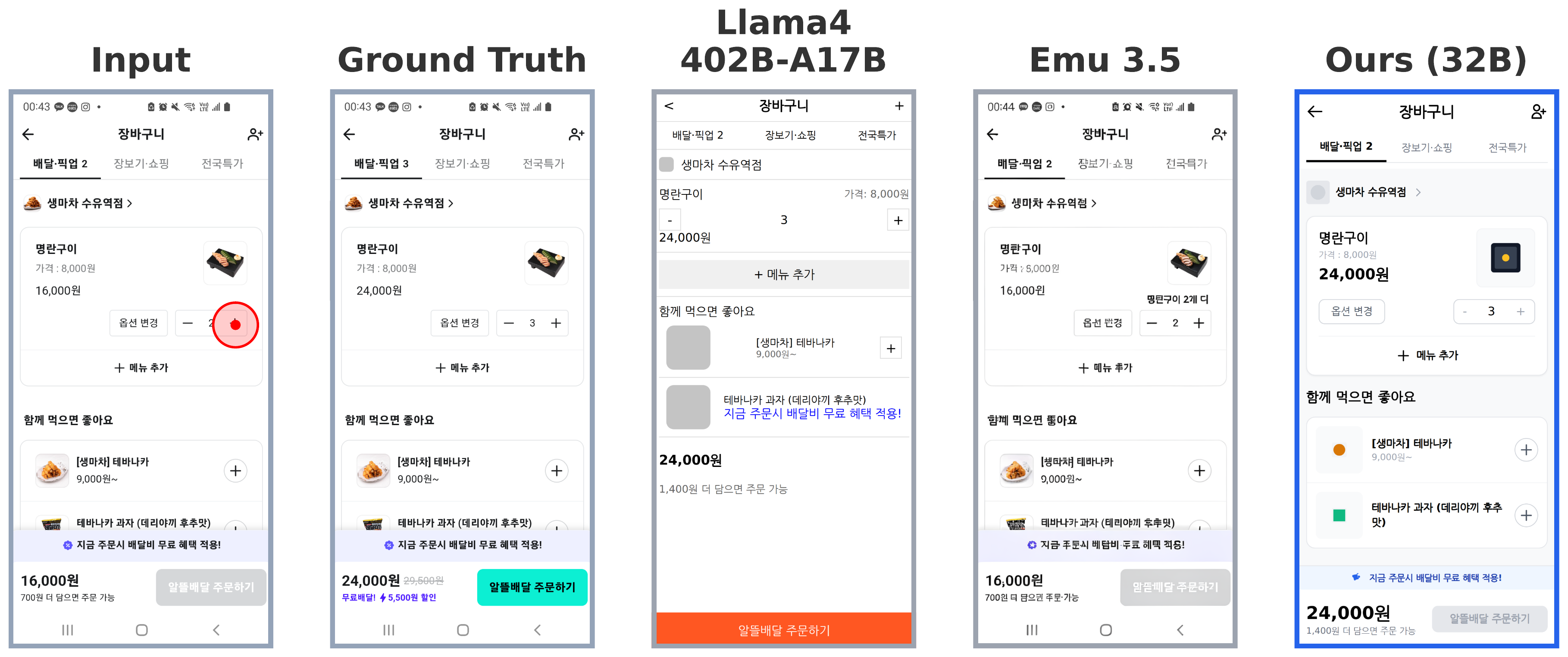
Mobile Graphical User Interface (GUI) World Models (WMs) offer a promising path for improving mobile GUI agent performance at train- and inference-time. However, current approaches face a critical trade-off: text-based WMs sacrifice visual fidelity, while the inability of visual WMs in precise text rendering led to their reliance on slow, complex pipelines dependent on numerous external models.
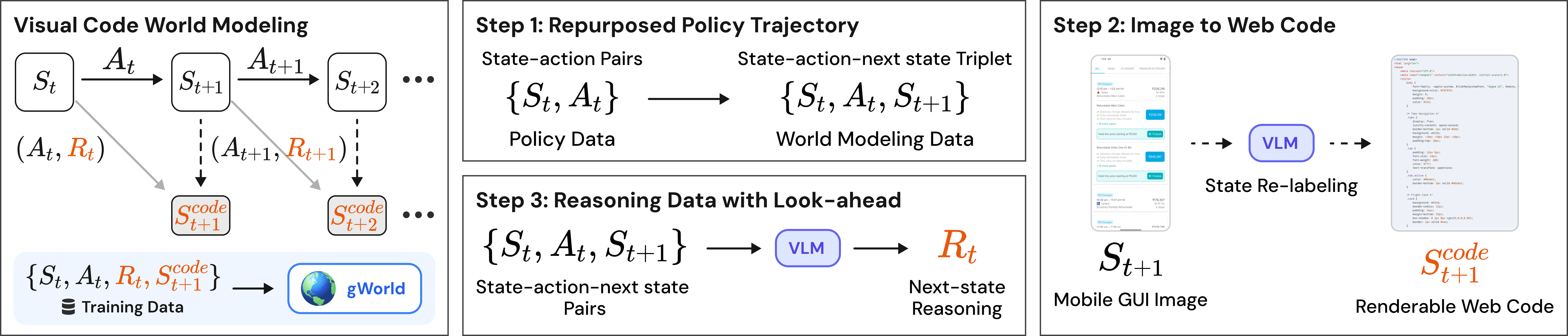
We propose a novel paradigm: visual world modeling via renderable code generation, where a single Vision-Language Model (VLM) predicts the next GUI state as executable web code that renders to pixels, rather than generating pixels directly. This combines the strengths of both approaches: VLMs retain their linguistic priors for precise text rendering while their pre-training on structured web code enables high-fidelity visual generation.
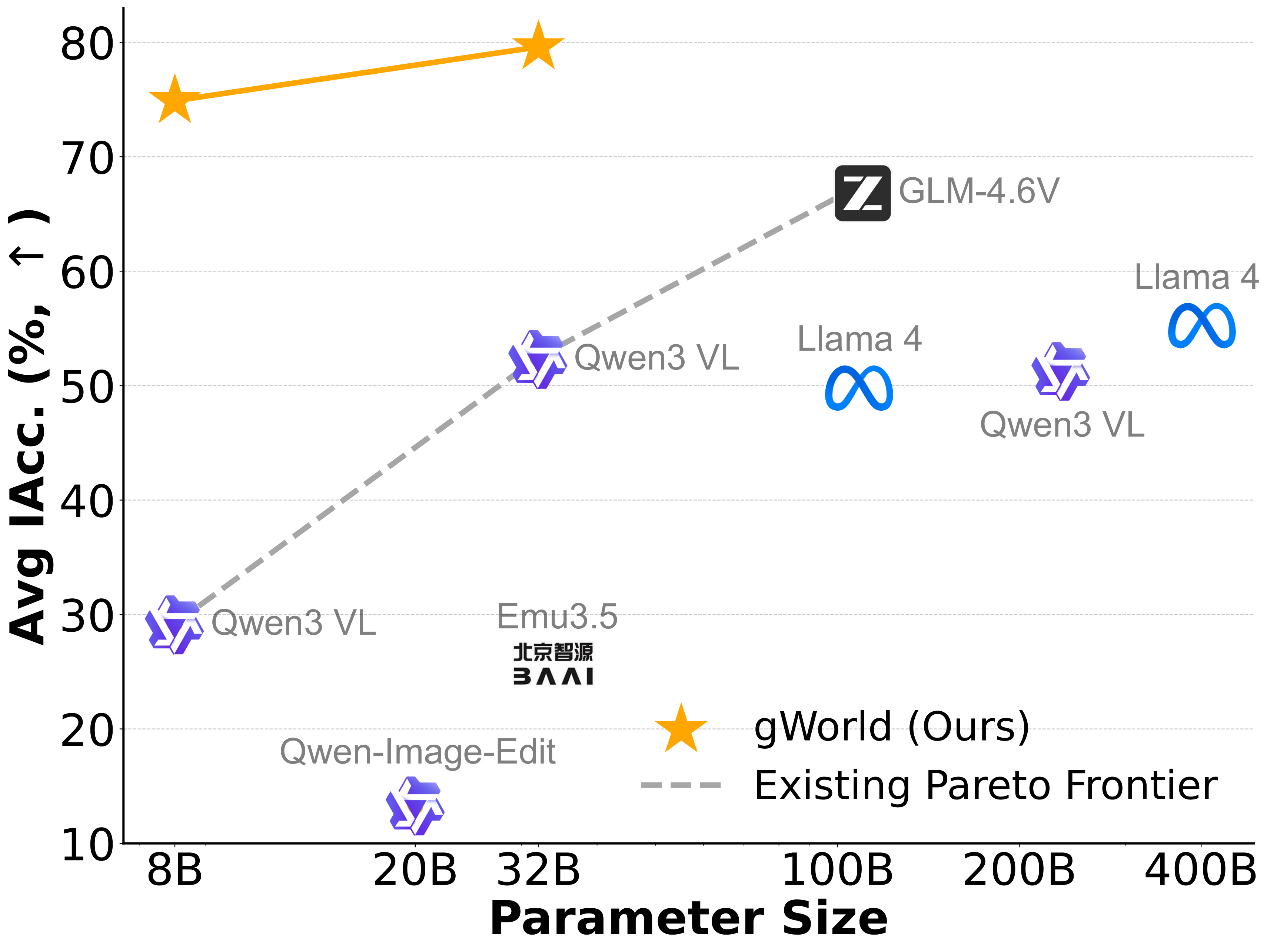
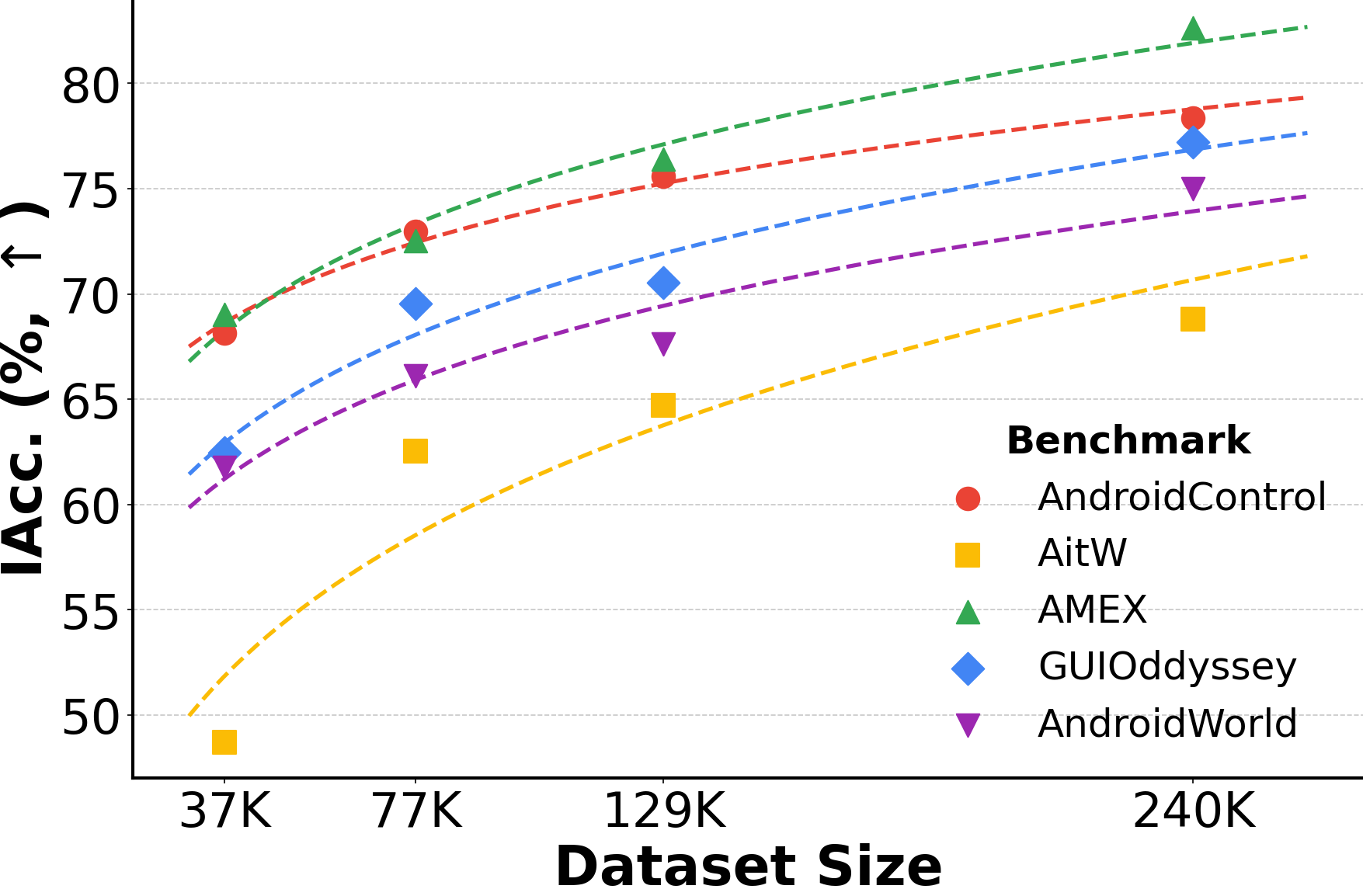
We introduce gWorld (8B, 32B), the first open-weight visual mobile GUI WMs built on this paradigm, along with a data generation framework that automatically synthesizes code-based training data. In extensive evaluation across 4 in-distribution and 2 out-of-distribution benchmarks, gWorld sets a new pareto frontier in accuracy versus model size, outperforming 8 frontier open-weight models over 50.25× larger.